Research
For a complete list of publications, please see the Google Scholar page.
2024
-
 FlexAttention for Efficient High-Resolution Vision-Language Models
FlexAttention for Efficient High-Resolution Vision-Language Models -

-
COMBO: Compositional World Models for Embodied Multi-Agent Cooperation
-
 SALMON: Self-Alignment with Instructable Reward Models
SALMON: Self-Alignment with Instructable Reward Models -
 Thin-Shell Object Manipulations With Differentiable Physics Simulations
Thin-Shell Object Manipulations With Differentiable Physics Simulations -
 Visual Chain-of-Thought Prompting for Knowledge-Based Visual ReasoningIn AAAI Conference on Artificial Intelligence
Visual Chain-of-Thought Prompting for Knowledge-Based Visual ReasoningIn AAAI Conference on Artificial Intelligence -
 Building Cooperative Embodied Agents Modularly with Large Language Models
Building Cooperative Embodied Agents Modularly with Large Language Models -
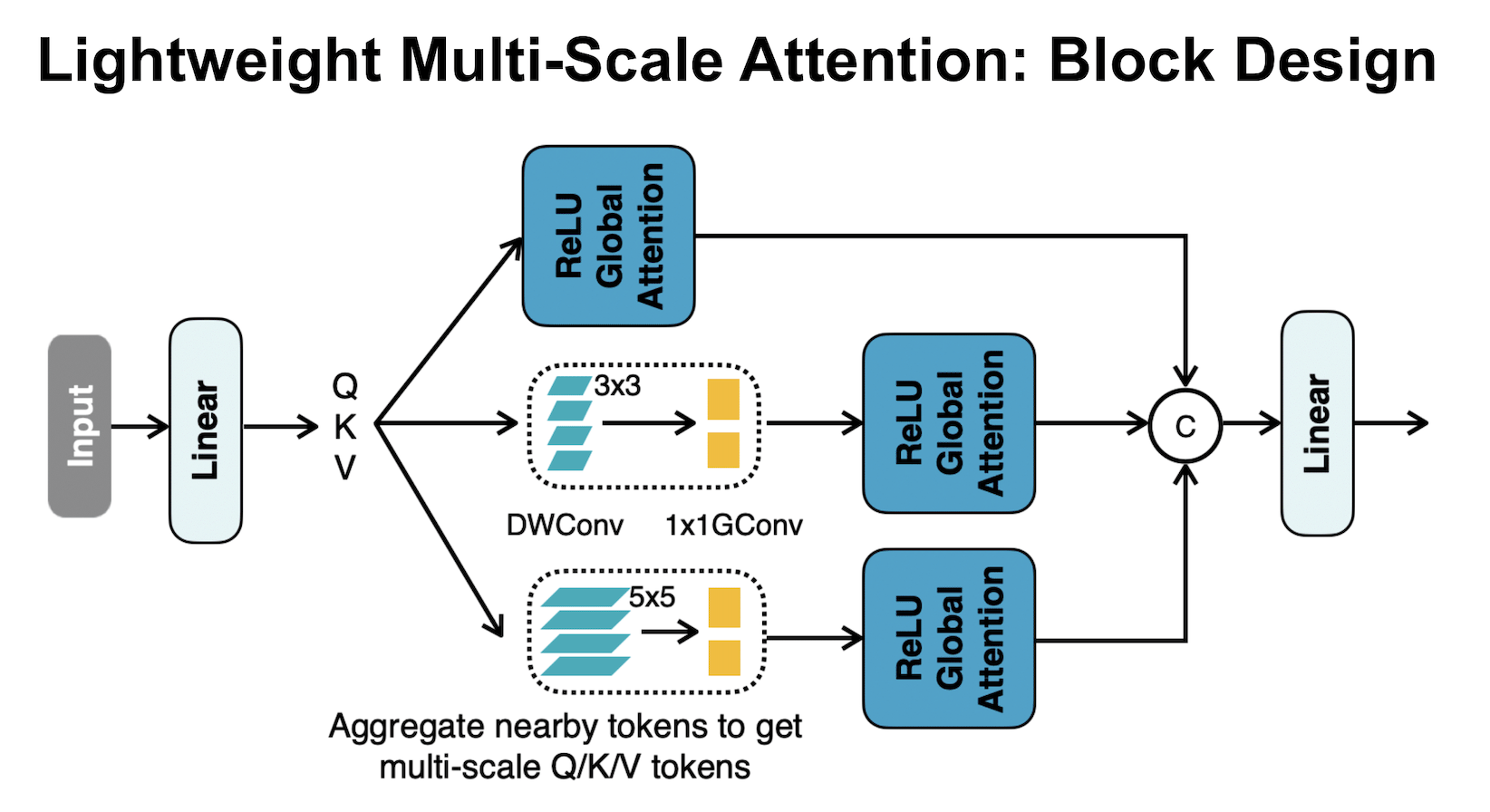 EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction
EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction -
HAZARD Challenge: Embodied Decision Making in Dynamically Changing Environments
-
MultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World
2023
-
DCIR: Dynamic Consistency Intrinsic Reward for Multi-Agent Reinforcement Learning
-
CoVLM: Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding
-
-

-
 Masked Motion Encoding for Self-Supervised Video Representation Learning
Masked Motion Encoding for Self-Supervised Video Representation Learning
2022
-
Learning Active Camera for Multi-Object Navigation
-
Weakly-Supervised Multi-Granularity Map Learning for Vision-and-Language Navigation
2021
-
RSPNet: Relative Speed Perception for Unsupervised Video Representation Learning
2020
-
Relation Attention for Temporal Action LocalizationIEEE Transactions on Multimedia
-
Location-aware Graph Convolutional Networks for Video Question Answering
-
Generating Visually Aligned Sound From VideosIEEE Transactions on Image Processing
-
Foley Music: Learning to Generate Music from Videos
-
Dense Regression Network for Video Grounding
2019
-
Breaking Winner-Takes-All: Iterative-Winners-Out Networks for Weakly Supervised Temporal Action LocalizationIEEE Transactions on Image Processing
-
Self-supervised Moving Vehicle Tracking with Stereo Sound